

{kind=link}

Introduction
Splunk is a powerful software platform for monitoring, searching, analysing, and visualising data created by machines in real time. It creates graphs, alerts, dashboards, and visualisations by capturing, indexing, and correlating real-time data in a searchable container.
Splunk is a programme that allows you to track and search enormous amounts of data. It indexes and correlates data in a searchable container and allows alarms, reports, and visualisations to be generated.
Splunk is a software platform that allows you to search, analyse, and display machine-generated data acquired from your IT infrastructure and business’s websites, applications, sensors, and devices.
How would you assess the machine condition in real time if you have a machine that generates data on a continuous basis? Can you do it with Splunk’s help? Yes! You certainly can. The illustration below illustrates how Splunk collects data.
Splunk’s main selling point is real-time processing since, while storage devices and processors have improved over time and become more efficient with each passing day, data transmission has not. This technique has not improved, and it is the bottleneck in the majority of organisational procedures.
If you already think Splunk is a fantastic tool, believe me when I say that this is only the beginning. If you want to provide your organisation with the greatest solution, whether it’s for system monitoring or data analysis, you can rest assured that the rest of this blog article will keep you glued to your seat.
What is Splunk?
Splunk is a powerful software platform for monitoring, searching, analysing, and visualising data created by machines in real time. It creates graphs, alerts, dashboards, and visualisations by capturing, indexing, and correlating real-time data in a searchable container. Splunk enables easy access to data throughout the whole enterprise, allowing for quick diagnoses and solutions to a variety of business issues.
In the year 2003, Rob Das and Eric Swan co-founded this technology as a response to all of the questions presented when researching the information caves that most businesses encounter. Splunk gets its name from the word ‘spelunking,’ which refers to exploring information caves. It was created to serve as a search engine for log files kept in a system’s infrastructure.
Splunk’s first version was released in 2004, and it was well received by its users. Slowly but steadily, it grew popular among most businesses, and they began to purchase enterprise licences. The founders’ major goal is to mass-market this emerging technology so that it can be used in practically any scenario.
Why do we need Splunk?
The Splunk Monitoring tool has a lot of advantages for an organization. The following are some of the advantages of applying Splunk:
- In a dashboard, it provides a better user interface and real-time visibility.
- By giving quick results, it cuts down on troubleshooting and resolution time.
- It’s an excellent tool for determining the source of a problem.
- You can create graphs, alerts, and dashboards with Splunk.
- Splunk makes it simple to search for and explore specific results.
- It enables you to troubleshoot any failure circumstance and improve performance.
- Assists you in keeping track of any business indicators and making informed decisions.
- Artificial Intelligence (AI) can be integrated into your data strategy with Splunk.
- Allows you to mine your machine data for relevant operational intelligence.
- Taking relevant information from several logs and summarising it.
- Splunk accepts any data format, including.csv, json, log formats, and so on.
- Provides users of all types with the most sophisticated search, analysis, and visualisation capabilities.
- Creates a central store for searching Splunk data from a variety of sources.
Advantages of Splunk
The key advantage of applying Splunk is that it makes data from systems (of any kind) easy to understand. However, the benefits of Splunk software are considerably more cross-cutting, such as the capacity to build dashboards and graphs from data, making it easier to share analyses at all levels of the organisational hierarchy. Splunk is also a scalable and simple-to-integrate platform that saves time and money in IT operations through real-time monitoring.
There are numerous advantages to using Splunk:
performs specific searches
- Contributes to the adoption of a data-driven approach in the organisation by converting complex data into simple information and monitoring operational flows in real time.
Scalable and simple to implement - In order to index all of your IT data in real time, you must do so on a regular basis.
- You won’t have to look for relevant information in your data because it will be discovered automatically.
- Get instant answers by searching your physical and virtual IT infrastructure for absolutely anything of interest.
- To make your system smarter, save searches and tag useful information.
- Create alerts to automate your system’s monitoring for specified recurrent events.
- Create and share analytical reports that include interactive charts, graphs, and tables.
- Share saved searches and reports with fellow Splunk users, and distribute their results to team members and project stakeholders via email.
- Examine your IT systems ahead of time to avoid server outages and security breaches.
Disadvantages of Splunk
The following are some limitations to utilising the Splunk tool:
- Splunk can be costly if you have a lot of data.
- Dashboards are useful, but they aren’t as powerful as other monitoring tools.
- It has a steep learning curve, and because it’s a multi-tier architecture, you’ll need Splunk training. As a result, you will need to devote a significant amount of effort to mastering this tool.
- Regular expressions and search syntax, in particular, are tough to comprehend.
Splunk Architecture
Splunk Certified specialists are in high demand, owing to the ever-increasing amount of machine-generated log data generated by practically every advanced technology that is shaping our world today. It’s critical to understand how Splunk works inside if you want to install it in your infrastructure. This blog was intended to help you understand the Splunk architecture and how the various Splunk components interact with one another.
If you want to learn more about Splunk, check out the Splunk Certification, which will teach you how to use it and why it is necessary for enterprises with large infrastructures.
Before I go into detail about how different Splunk components work, I’d like to go over the various stages of the data pipeline that each component belongs to.
The Stages of the Data Pipeline
In Splunk, there are mainly three stages:
- Data Input stage
- Data Storage stage
- Data Searching stage

Data Input Stage
Splunk software consumes the raw data stream from its source at this stage, breaking it down into 64K blocks and annotating each block with metadata keys. The metadata keys include the data’s hostname, source, and source type. Internal values, such as data stream character encoding, and values that affect data processing during the indexing step, such as the index into which the events should be stored, can also be included in the keys.
Data Storage Stage
Parsing and indexing are the two stages of data storage.
Splunk software evaluates, analyses, and transforms data in the parsing phase to extract just the essential information. Event processing is another name for this. Splunk software divides the data stream into distinct events during this step. There are several sub-phases in the parsing phase:
- separating the data stream into several lines
- Identifying, processing, and establishing timestamps are all part of the process.
- Metadata is copied from the source-wide keys and annotated on individual events.
- Regex transform rules are used to transform event data and metadata.
Splunk software writes parsed events to the index on disc during the indexing process. It saves both compressed raw data and the index file that goes with it. Indexing has the advantage of making data more accessible during searches.
Data Searching Stage
The user’s ability to access, read, and use the indexed data is controlled at this point. Splunk software maintains user-created knowledge objects including reports, event kinds, dashboards, alerts, and field extractions as part of its search capability. The search feature also controls how the search is carried out.
Splunk Components
You can see the many data pipeline stages that various Splunk components fall into in the graphic below.
Splunk is made up of three key components:

- Splunk Forwarder is a data forwarding application.
- The Splunk Indexer is a data indexing and parsing application
- Search Head is a graphical user interface (GUI) for finding, analysing, and reporting data.
Splunk Forwarder
Splunk Forwarder is the component you’ll need to collect the logs with. If you wish to collect logs from a distant system, you can do so with Splunk’s remote forwarders, which are separate from the main Splunk instance.
In fact, you can set up numerous forwarders on different devices to send log data to a Splunk Indexer for processing and storage. What if you want to analyse data in real time? Splunk forwarders can also be utilised for this. The forwarders can be set up to feed data to Splunk indexers in real time. They can be installed in numerous systems and collect data in real time from multiple devices at the same time.
Splunk Forwarder uses 1-2% of the CPU when compared to other standard monitoring tools. They can readily scale to tens of thousands of remote systems and capture gigabytes of data with minimal performance impact.
Universal Forwarder
If you wish to send the raw data collected at the source, you can use a universal forwarder. It’s a straightforward component that conducts very basic processing on receiving data streams before passing them on to an indexer.
With practically every tool on the market, data transfer is a huge issue. Because data undergoes minimum processing before being transferred, a large amount of superfluous data is forwarded to the indexer, resulting in performance overheads.
Why go through the trouble of uploading all of the data to the Indexers only to have only the pertinent data filtered out? Isn’t it more efficient to send only the necessary data to the Indexer, saving bandwidth, time, and money?
Heavy Forwarder
Because one level of data processing occurs at the source before data is forwarded to the indexer, you can utilise a Heavy forwarder to solve half of your difficulties. The Heavy Forwarder parses and indexes data at the source and intelligently sends it to the Indexer, saving bandwidth and storage space. As a result, when the data is parsed by a heavy forwarder, the indexer just has to deal with the indexing segment.
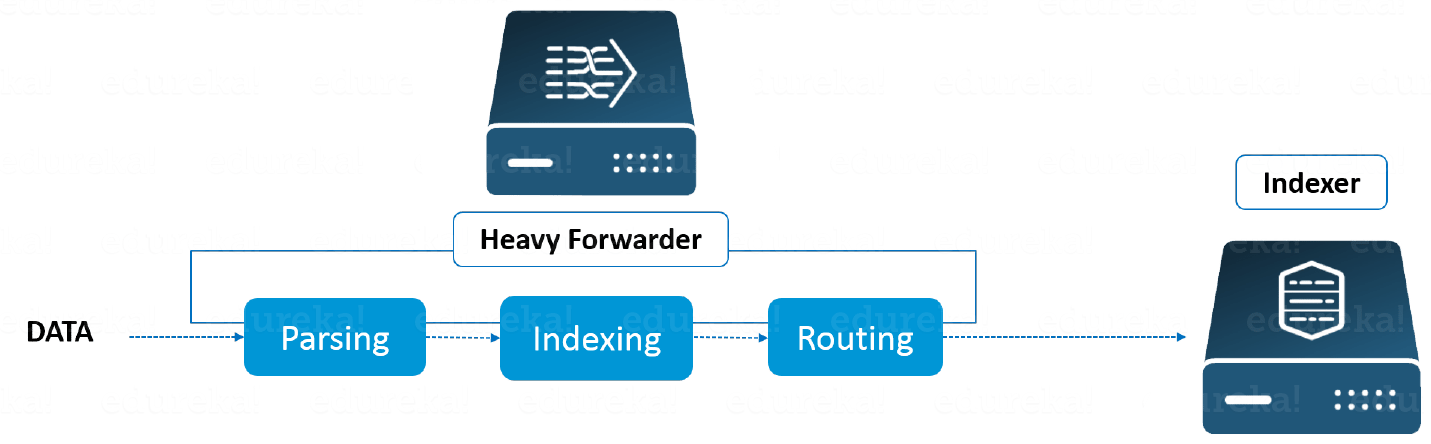
Splunk Indexer
The indexer is a Splunk component that will be used to index and store the data received from the forwarder. Splunk converts incoming data into events and stores it in indexes so that search operations can be performed quickly. If you’re getting data from a Universal forwarder, the indexer will parse it first before indexing it. The purpose of data parsing is to remove any unnecessary information. If the data comes from a Heavy forwarder, however, the indexer will just index the data.
Splunk creates a number of files when it indexes your data. One of the following can be found in these files:
- In compressed form, raw data
- Index files (also known as tsidx files) that point to raw data, as well as certain metadata files
These files are stored in buckets, which are collections of directories.
Now, let me explain how indexing works.
Splunk processes incoming data so that it may be searched and analysed quickly. It enhances data in a number of ways, including:
- Separating the data stream into separate events that can be searched
- Making or locating timestamps
- Fields like host, source, and source type are extracted.
- Identifying custom fields, concealing sensitive data, writing new or changed keys, applying breaking rules for multi-line events, filtering undesired events, and routing events to specified indexes or servers are all examples of user-defined actions that can be performed on incoming data.
Event processing is another name for this indexing procedure.
Data replication is another advantage of using Splunk Indexer. Splunk keeps several copies of indexed data, so you don’t have to worry about data loss. Index replication, also known as Indexer clustering, is the name given to this procedure. An Indexer cluster, which is a group of indexers configured to replicate each other’s data, is used to do this.
Splunk Search Head
The component that interacts with Splunk is the search head. It gives customers a graphical user interface via which they can conduct numerous tasks. You can use search words to search and query the data contained in the Indexer, and you will get the desired results.
The search head can be installed on separate servers or on the same server as other Splunk components. There is no separate installation file for the search head; it is simply enabled by enabling the Splunk web service on the Splunk server.
A Splunk instance can serve as a search head as well as a search peer. A dedicated search head is one that does solely searching and not indexing. A search peer, on the other hand, indexes data and replies to search requests from other search heads.
A search head can submit search queries to a set of indexers, or search peers, in a Splunk instance, who then do the actual searches on their indexes. The search head then combines the results before returning them to the user. Distributed searching is a strategy for searching data that is faster.
The search efforts are coordinated by search head clusters, which are groups of search heads. The cluster manages the search heads’ activities, assigns work depending on current loads, and guarantees that all search heads have access to the same set of knowledge items.
The deployment server, as previously stated, is used to manage the whole deployment, including configurations and policies.
- By using scripts to automate data forwarding, you can receive data from a variety of network ports.
- You may keep an eye on the files as they arrive and detect any changes in real time.
- Before it reaches the indexer, the forwarder can intelligently route the data, clone the data, and perform load balancing on it. Cloning is used to produce several copies of an event at the data source, while load balancing is used to ensure that data is passed to another server hosting the indexer even if one instance fails.
- The deployment server, as previously stated, is used to manage the whole deployment, including configurations and policies.
- This information is received and stored in an Indexer. The indexer is then divided into logical data stores, and permissions can be established for each data store to control what each user sees, accesses, and uses.
- You can search the indexed data and also spread queries to other search peers, and the results will be integrated and returned back to the Search head once the data is in.
- Aside from that, you may run scheduled searches and set up alerts to be activated when certain conditions match previous searches.
- Using Visualization dashboards, you can build reports and analyse saved searches.
- Finally, Knowledge objects can be used to enrich unstructured data.
Features of Splunk
In this part, we’ll go over the key features of the enterprise edition.
Data Ingestion:
Splunk accepts a wide range of data formats, including JSON, XML, and unstructured machine data such as web and application logs. The user can model the unstructured data into a data structure as desired.
Data Indexing
Splunk indexes ingested data to allow for faster searching and querying in a variety of situations.
Data Searching
Searching in Splunk requires creating measurements, forecasting future trends, and detecting patterns in the data utilising the indexed data.
Using Alerts
When certain criteria are detected in the data being analysed, Splunk alerts can be used to send emails or RSS feeds.
Dashboards
Splunk Dashboards can display search results in the form of graphs, reports, and pivot tables, among other things.
Modelling Data
Based on specialised domain knowledge, the indexed data can be represented into one or more data sets. This allows end users to traverse and comprehend business cases without having to know Splunk’s complicated search processing language.
Splunk Products
- Advanced Threat Detection is a term that refers to the detection of advanced threats.
- DevOps.
- Modernization of applications.
- Forensics and incident investigation
- Automate and coordinate the SOC.
- Detection of Insider Threats.
- Cloud migration is a word used to describe the process of migrating data from one location to another.
- Modernization of information technology.
Applications of Splunk
- Splunk’s applications include monitoring, machine analysis, security, and business performance.
- Splunk Enterprise offers a comfortable environment that expands from specialised use cases to an enterprise-wide analytics backbone, thanks to straightforward analysis features, machine learning, packaged apps, and open APIs.
- A Splunk application is nothing more than a well-organized set of configurations and assets that work together to accomplish a certain goal, such as data collecting, indexing, and visualisation.
- You must be able to navigate in order to create a successful Splunk application. You’d be working on an add-on if the application didn’t have navigation.
- Vendors Dynatrace and Extra hop have built Splunk apps to enable users see their deep-dive application performance data in the context of all other application data such as logs, events, and infrastructure performance.
Best Practices of using Splunk
- Configure the audit policy for Active Directory.
- Install the Splunk Add-on for Microsoft Active Directory and configure it.
- Install the Microsoft Active Directory Splunk Add-on.
- Confirm and troubleshoot the gathering of AD data.
- Searches and dashboards examples
- Use easy-to-understand key-value pairs.
- Create events that can be read by humans.
- For each event, use timestamps.
- Make use of identifiers that are unique (IDs)
- Log in using plain text.
- Make use of formats that are user-friendly to programmers.
- More than only debugging events should be recorded.
- Make use of categories.
How will Splunk help in your career growth?
Splunk is one of the most in-demand tools in the market right now, thus a job in it ensures a bright future. Do you know why there’s been so much talk about Splunk lately? From unstructured data, it generates intelligent insights about customers, their trends & patterns, behaviour, and so forth.
Yes, you read that correctly. Unstructured data is no longer considered “trash.” Apparently, it is the treasure house that provides companies with further information. So, in this blog, we’ll look at the exciting career options and growth that Splunk has to offer.
Splunk can be used by almost any company that deals with massive amounts of data. Also, professional opportunities in Splunk do not appear to have dried up in any of the industries recently. The following industries, on the other hand, rely heavily on Splunk.
It also provides assistance to government organisations, colleges, and service providers in every country. As a result, Splunk is now used by over 9000 enterprises to obtain in-depth information of their customers and business, mitigate risks, reduce expenses, and improve overall performance. As a result, you can see exponential increase in Splunk use around the world.
Start learning Splunk if you’re interested in the employment options it provides and want to build a successful career path. Administrator, Architect, and Developer are the three key responsibilities in a Splunk career. These careers offer a variety of tasks and responsibilities, so it’s crucial to figure out which one appeals to you the most.
As a result, take the Splunk course as needed, and if you’re searching for a reputable online academy in the United States to learn Splunk, look no further than Cyber Chasse Learning Academy. It provides a professional yet free consultation to assist you in selecting the appropriate course.
Future For Splunk
Businesses currently draw insights from about 7% of data, which is clearly insufficient to catapult profits. Large amounts of unstructured data, on the other hand, continue to accumulate, and it is estimated that by 2022, roughly 93 percent of all data will be unstructured.
Existing unstructured data volumes are not being managed and stored effectively. This only demonstrates how companies will be on the search for capable Splunk experts in the near future. As a result, starting a career in Splunk is the best move one can make.
Conclusion
Splunk offers a promising career path due to the constant rise of unstructured data and the increasing need for skilled Splunk specialists. If you are a qualified Splunk professional searching for work in the United States, register with Cyber Chasse Staffing Services to get your dream job with one of the Fortune 500 firms. However, if you are new to Splunk and want to pursue a career in it, Cyber Chasse Learning Academy offers well-curated courses that will help you get work swiftly.
Source: GreatLearning Blog